German Research Foundation (Deutsche Forschungsgemeinschaft, DFG).
Semantic and Local Computer Vision based on Color/Depth Cameras in Robotics (SeLaVi)
Abstract (deutsch)
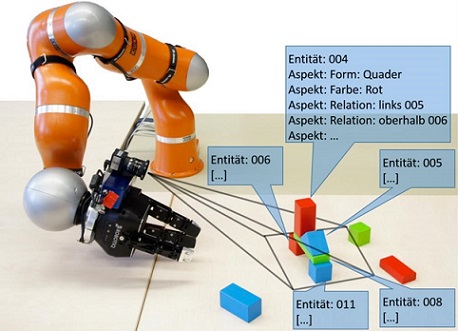
Für moderne Roboter ist die Erkennung von Objekten in ihrer Umgebung eine zentrale Fähigkeit, welche erst nützliche und flexible Handlungen ermöglicht. Dazu werden zumeist ein oder mehrere Kamerabilder der Szene ausgewertet und eine interne Repräsentation der Umwelt für den Roboter aufgebaut. Die bildbasierte Objekterkennung ist aber mit einigen Schwierigkeiten konfrontiert: Einerseits werden geometrisch einfache und schwach texturierte Gegenstände, wie sie in vielen Anwendungen auftreten, kaum erkannt. Andererseits werden (teil-)verdeckte Objekte in der Szene schlechter oder gar nicht wahrgenommen. Darüber hinaus beschreibt die sensorisch erfasste Information zumeist nur Geometrie und Lage der einzelnen Objekte, nicht aber deren semantische Funktion oder Beziehungen untereinander (z. B. „A liegt auf B“). Dagegen sollte die Perzeption als Fernziel die Umgebung so „verstehen“, dass die verschiedenen Gegenstände einer komplexen Szene mittels Roboter sinnvoll manipuliert werden können. Außerdem sollten wenige, lokale Sichten auf die Szene ausreichen, um eine möglichst vollständige, globale Umweltrepräsentation erzeugen zu können. In dem beantragten Forschungsprojekt „SeLaVi“ werden neue Konzepte zum bildbasierten Verstehen einer Szene entwickelt und untersucht. Als neuer und einzigartiger Grundansatz dienen geometrische Modelle, welche die Objekte durch wenige Oberflächenstücke darstellen (Boundary Representations, BReps) und aus einem oder mehreren Tiefenbildern erzeugt werden. Dadurch ist eine deutlich höhere Speicher- und Recheneffizienz der Verfahren gewährleistet, als mit den sonst üblichen Punktwolken oder Dreiecksnetzen möglich ist. Basierend auf dem BRep und auf zusätzlicher Farbinformation aus der Szene werden die darin enthaltenen Objekte einer Objektdatenbank wiedererkannt. Die Erkennung der statischen Objekte soll mit wenigen lokalen Sichten auf die Szene arbeiten und möglichst robust gegenüber sonstigen bewegten Objekten (z. B. Menschen) sein. Das so erstellte Weltmodell wird dann um semantische Relationen zwischen den Objekten erweitert, um deren Manipulation durch einen Roboterarm zu ermöglichen. Ergänzend wird der semiautomatische Aufbau der Objektdatenbank durch den Benutzer betrachtet. Die potentiellen Anwendungsgebiete reichen von autonomen Servicerobotern, über das Programmieren-durch-Vormachen und die Mensch/Roboter-Kooperation, bis hin zur industriellen Automatisierung (z. B. Griff-in-die-Kiste).
Keywords: Objekterkennung, Computersehen, Robotik, Angewandte Informatik
Abstract (english)
For modern robots, recognizing objects in their environment is a key skill that enables useful and flexible actions. For this purpose, usually one or more camera images of the scene are evaluated and an internal representation of the environment for the robot is built. However, image-based object recognition is confronted with some difficulties: on the one hand, geometrically simple and slightly textured objects, as they occur in many applications, are barely recognized. On the other hand, (partially) hidden objects in the scene are perceived worse or not at all. In addition, the sensory information usually describes only the geometry and location of the individual objects but not their semantic function or relationships with each other (e.g., "A is on B"). By contrast, perception as a long-term goal should "understand" the environment so that the various objects of a complex scene can be meaningfully manipulated by means of robots. In addition, few local views on the scene should be sufficient to create the most complete global environmental representation possible. The proposed research project "SeLaVi" develops and examines new concepts for image-based understanding of a scene. As a new and unique basic approach serve geometric models, which represent the objects by few surface patches (Boundary Representations, BReps) and which are generated from one or more depth images. This ensures a significantly higher storage and computational efficiency of the method than is possible with the common point clouds or triangular networks. Based on the BRep and on additional color information from the scene, the objects of an object database are recognized. The recognition of the static objects should work with few local views on the scene and be as robust as possible against other moving objects (for example humans). The world model created in this way is then extended by semantic relations between the objects in order to enable manipulation by a robot arm. In addition, the semi-automatic generation of the object database by the user is considered. The potential fields of application range from autonomous service robots, programming-to-programming and human/robot cooperation, to industrial automation (e.g., handle-in-the-box).
Keywords: object recognition, computer vision, robotics, applied computer science
Contact
Bilder
Press releases
Roboter lernen sehen: Bayreuther Forscher machen Serviceroboter intelligenter
(14. Februar 2019)
Wanted
Student Jobs / Open Positions
Publications
- Dorian Rohner; Johannes Hartwig; Dominik Henrich; (2022)
Detection and Handling of Dynamic Scenes during an Active Vision Process for Object Recognition using a Boundary Representation
(Annals of Scientific Society for Assembly, Handling and Industrial Robotics 2022)
https://doi.org/10.1007/978-3-031-10071-0 - David Harrer; Dominik Henrich; Dorian Rohner; (2022)
Robot-Based Creation of Complete 3D Workpiece Models
(Annals of Scientific Society for Assembly, Handling and Industrial Robotics 2021)
Link to publication - Dorian Rohner; Dominik Henrich; (2020)
Using Active Vision for Enhancing an Surface-based Object Recognition Approach
(2020 Fourth IEEE International Conference on Robotic Computing (IRC))
Link to publication - Dorian Rohner; Myriel Fichtner; Dominik Henrich; (2019)
Vision-based Generation of Precedence Graphs
( Annals of Scientific Society for Assembly, Handling and Industrial Robotics)
Link to publication - Dorian Rohner; Dominik Henrich; (2019)
Object Recognition for Robotics based on Planar Reconstructed B-Rep Models
(The Third IEEE International Conference on Robotic Computing)
Link to publication