Software
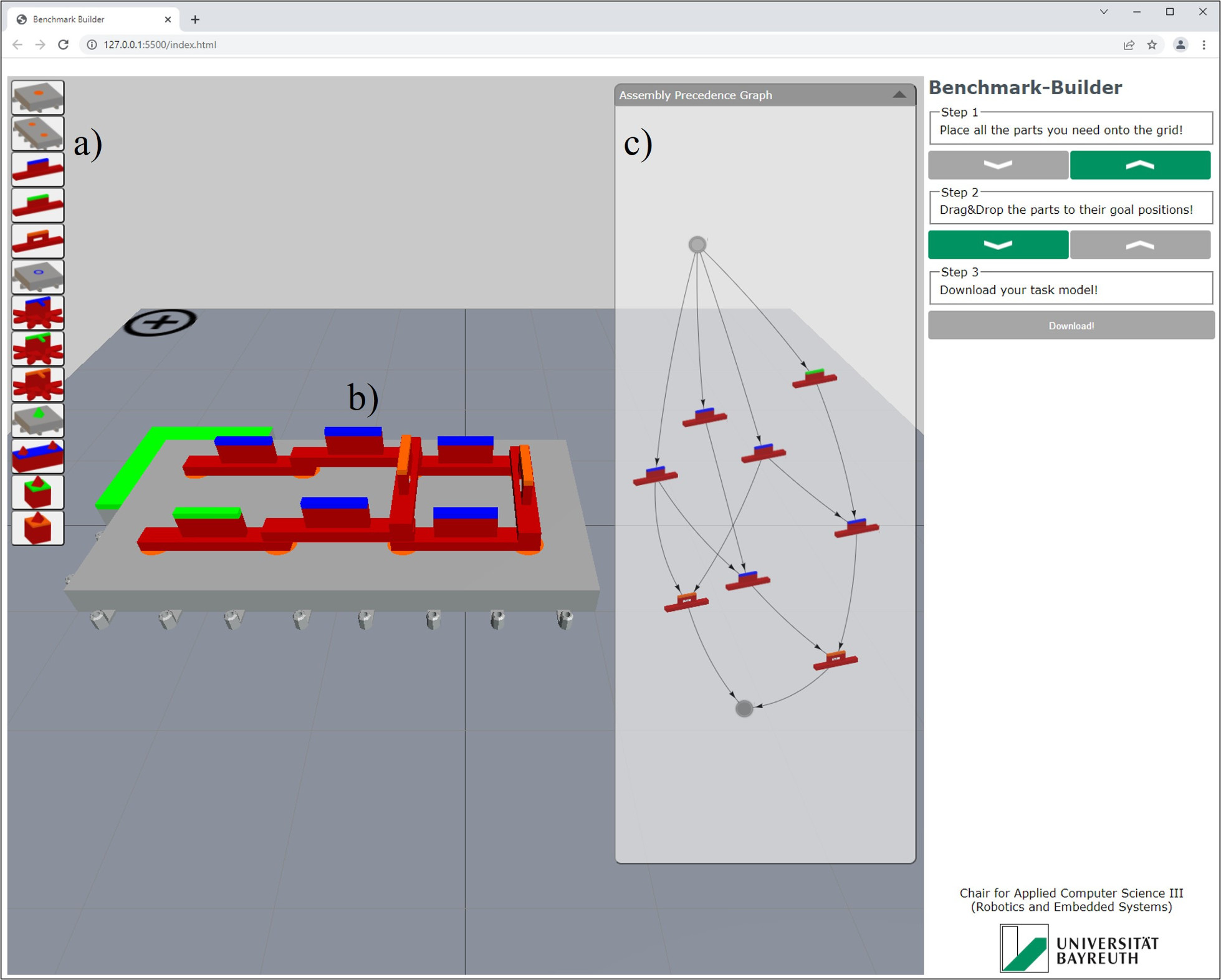
Benchmark Toolkit for Collaborative HRI
Novel human-robot interaction (HRI) approaches need careful validation. This is often achieved with user studies in laboratory environments, which mostly rely on highly individual, complex prototype setups in early design phases. Lately, the lack of replicability imposed by such experiments has vitally been discussed. Sharing common benchmark tasks among researchers would be a valuable basis to overcome this issue. We therefore offer a benchmark toolkit to compose scalable, synthetic standard tasks as a unified basis for future efforts towards more replicable HRI research.
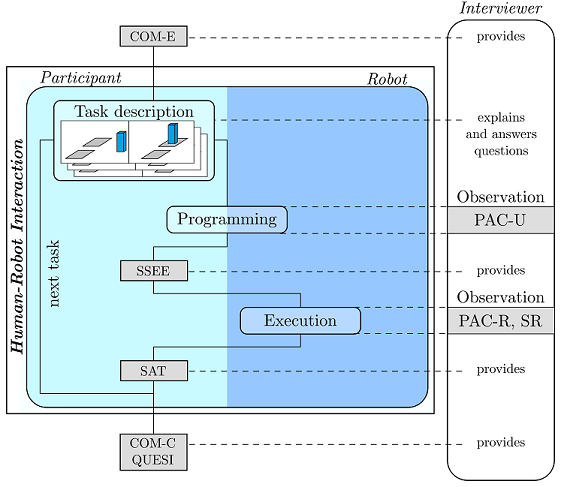
Evaluation Toolkit
Here we present a toolkit to evaluate robot programming concepts. This toolkit concerns in particular the intuitiveness of a programming interface and its robustness regarding the results from generated programs. We hope to engage robot programming developers in evaluating the acceptability of their approach, find strengths and weaknesses and finally improve the design of robots.